
Architecture

At the core of Hunter is a collaboration between HPE (Hewlett Packard Enterprise), Cray (now part of HPE), and AMD. The system is designed using the HPE Cray EX supercomputing architecture, designed specifically for exascale-class workloads and heterogeneous compute environments. Each Hunter node is built around AMD’s next-generation Accelerated Processing Units (APUs), combining high-performance Zen-based CPU cores with GPU accelerators using the CDNA 3.0 architecture.
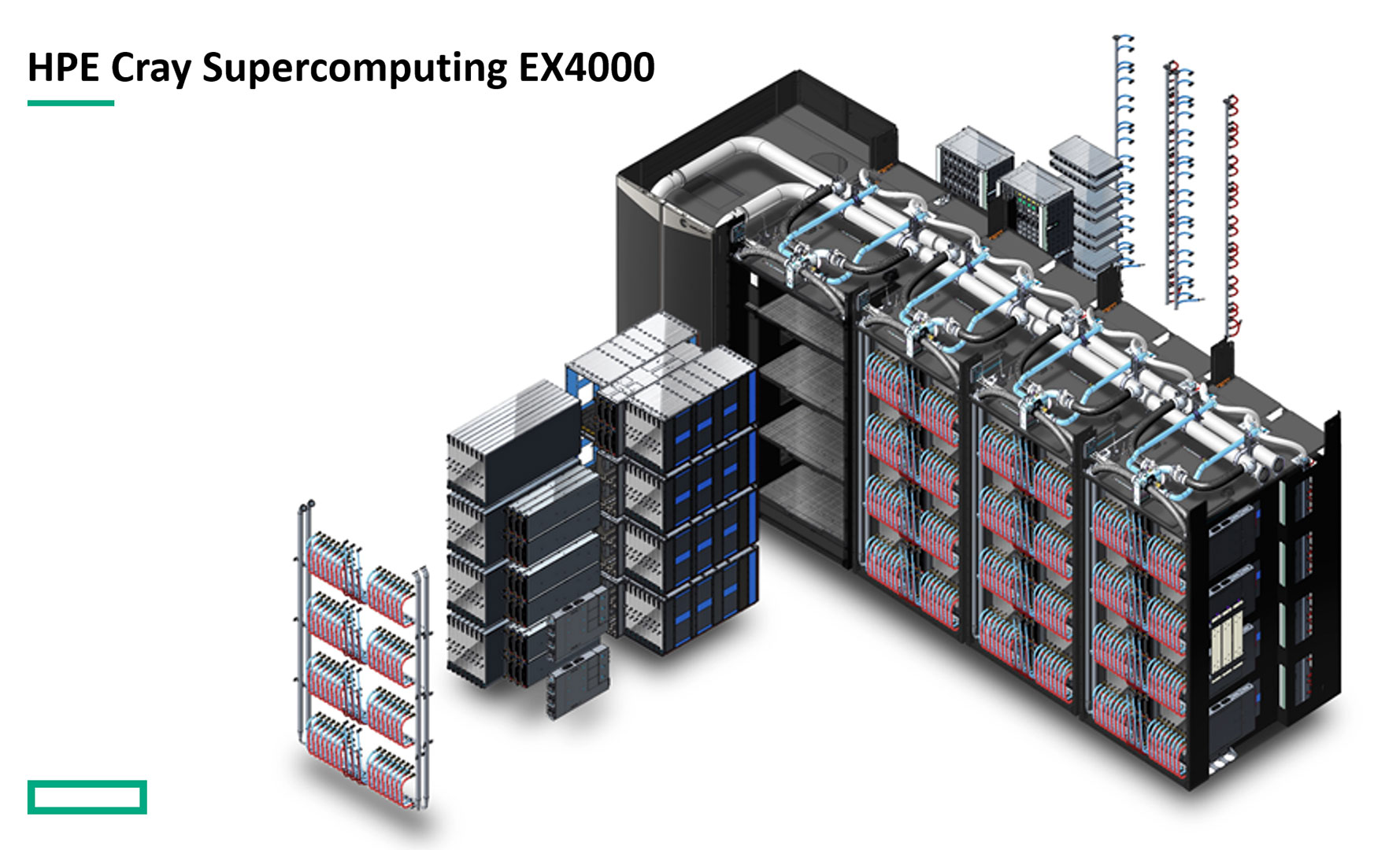
Just to clarify, what you see on the photo above is the whole supercomputer—it’s not like it occupies the whole building.



While “supercomputer” might sound similar to your PC case, just bigger and with even more expensive stuff inside, Hunter is actually a cluster of individual computers called “nodes.” Each of these nodes sits on a blade, a rectangular unit that can be pulled out for service and maintenance. Note the red and blue liquid hoses that provide cooling for each of the blades.

The “classic” compute infrastructure of Hunter consists of 512 AMD EPYC 9374F “Genoa” processors, with each processor featuring 32 cores, 64 threads, and 256 MB of cache. These processors can reach speeds of up to 4.3 GHz and have a TDP of 320 W. Two CPUs are grouped into 256 nodes, and each node is equipped with 768 GB of DDR5-4800 memory. Traditionally this was “the supercomputer.” But with Hunter, the HLRS is stepping into the world of GPU-powered computing.


In tandem with the CPUs—the system features 188 APU nodes, with each one of them comprised of four AMD MI300A APUs. Hunter is among the first large-scale deployments to fully utilize AMD’s Instinct MI300A accelerator, a chip that fuses CPU and GPU cores into a single coherent package. Rather than operating as separate devices connected via PCIe, the CPU and GPU share memory and cache coherently, dramatically reducing data movement penalties common in hybrid architectures.


Each of the APUs comes with 14,592 GPU cores and 128 GB of HBM3 memory, it also has 24 Zen 4 CPU cores. With 128 GB of HBM3 memory, each MI300A allows both the CPU and GPU to share resources in a memory coherent way. This is considered a major advantage since it avoids the expensive memory transfers typically required between the CPU and GPU over a bus such as PCIe. Also note how AMD uses 3D stacking to integrate several smaller silicon dies to form a larger processor.
The integration of CPU and GPU in a single package also opens the door for new kinds of converged workflows—where traditional simulation, data analytics, and AI components can be fused into a single application pipeline, working on the same data—that won’t have to be moved around all the time—thanks to the APU’s unified memory architecture. This enables more efficient and innovative problem-solving approaches, particularly in fields such as climate modeling, molecular dynamics, and engineering design.


The internal node interconnects and system-level fabric rely on the HPE Slingshot 11 Dragonfly networking architecture, which provides four 200 Gbit/s links per node to move data at incredible speeds. The first photo above shows the back of the system, i.e. the other side of the blades with the red/blue cooling hoses. On the second photo you can see the connectors for networking



Thermal management is handled via direct liquid cooling, above you can see one of the ports on a blade. Liquid cooling is extremely useful to handle the dense packaging and thermal output of modern the system, and it also results in a significant increase in energy efficiency compared to traditional air-cooled systems. As per the sheet in the second photo, the liquid used is not water, but “OAT PG-25.” OAT PG-25 is a computer coolant composed of 25% propylene glycol and organic acid inhibitors. It provides effective heat transfer, low toxicity, and long-term corrosion protection for mixed-metal cooling systems. Its low viscosity supports efficient flow with minimal pump load, making it ideal for liquid-cooled HPC environments.
We also spotted a large tape library, that provides huge amounts of additional storage at low cost. For traditional storage, Hunter uses a Cray ClusterStor E2000 storage system, featuring 2,120 disks with a total capacity of 25 petabytes.
Business Model and Access Policy
Hunter is operated by HLRS as a publicly funded facility under the jurisdiction of the state of Baden-Württemberg in Germany. The total cost was 15 million Euros. As such, it follows a non-commercial operational model: HLRS is neither allowed to generate profit from access to its systems, nor to provide subsidized compute to any particular user or institution. This neutrality shapes a pricing structure that reflects actual system and operational costs without markup or discount, providing a transparent and level playing field for all users.
Academic researchers—both from within Germany and internationally—form the majority of the user base, accessing the system via peer-reviewed grant allocations. However, commercial users can also gain access under specific frameworks—provided they adhere to the same cost structure and resource usage policies. This hybrid model ensures that commercial entities can benefit from state-of-the-art HPC capabilities for research, development, and engineering, without displacing academic priorities or receiving unfair economic advantage.
This framework makes Hunter notably competitive with commercial hyperscalers and cloud-based HPC services. While public cloud providers must factor in capital expenditure recovery, profit margins, and often overprovisioned infrastructure, HLRS can focus solely on cost recovery. This allows it to offer top-tier performance at rates that are often significantly lower than those of cloud platforms—particularly for long-duration or tightly coupled parallel workloads that are not cloud-native. It also ensures full transparency and predictability in resource planning for users operating under constrained research budgets.
It was also mentioned to us that hyperscalers are obligated to offer very high availability guarantees exceeding 99.99%, whereas HLRS does not, leading to a significant cost advantage. For example, they don’t need to construct massive UPS units, diesel power generators, or fuel storage facilities.


